 "Personally, I find that when looking for security vulnerabilities, a good place to start are those places where developers probably don't know what they are doing, but feel really good about the solution they implement." Moxie Marlinspike, www.thoughtcrime.orgCyLab Seminar Series Notes: The Evolution of A Hacking Tool, Moxie Marlinspike on SSLstrip[NOTE: CyLab's weekly seminar series provides a powerful platform for highlighting vital research. The physical audience in the auditorium is composed of Carnegie Mellon University faculty and graduate students, but CyLab's corporate partners also have access to both the live stream and the archived content via the World Wide Web. From time to time, CyBlog will whet your appetite by offering brief glimpses into these talks. Here are some of my notes from a talk delivered by independent researcher Moxie Marlinspike on 5-18-09. -- Richard Power]
"Personally, I find that when looking for security vulnerabilities, a good place to start are those places where developers probably don't know what they are doing, but feel really good about the solution they implement." Moxie Marlinspike, www.thoughtcrime.orgCyLab Seminar Series Notes: The Evolution of A Hacking Tool, Moxie Marlinspike on SSLstrip[NOTE: CyLab's weekly seminar series provides a powerful platform for highlighting vital research. The physical audience in the auditorium is composed of Carnegie Mellon University faculty and graduate students, but CyLab's corporate partners also have access to both the live stream and the archived content via the World Wide Web. From time to time, CyBlog will whet your appetite by offering brief glimpses into these talks. Here are some of my notes from a talk delivered by independent researcher Moxie Marlinspike on 5-18-09. -- Richard Power]In the late 1990s, as electronic commerce (and cyber crime) started heating up, I got many calls from reporters asking the same question over and over again, “Is it safe to use our credit cards over the Web?”
In response, I would point out that this was the wrong question. The right question, the bigger question, was lost on them, i.e., “What is going to happen to your credit card information at the other end of the transaction?”
The point I was driving home was that the turning over of insecure server brimming with credit card records was going to be the cyber crime of the decade, not the petty cyber theft of one credit card transaction.
As the years passed, and the aggregation of tens of thousands of credit cards on those servers turned into aggregates of hundreds of thousands of credit cards, and then in turn, millions and tens of millions of credit cards, my warning turned into an everyday fact of life in cyberspace.
But back then, for everyone one of us, who was trying to direct the attention of the public (and those paid to inform it) away from the vulnerability of a single transaction to the greater threat of digital stagecoach robberies, there were a dozen vendors and consultants waiting in line to answer those reporters in a much more simplistic (and misleading) way, “Yes, of course, it is safe, because we have SSL.”
I was reminded of this subplot in the cyber risk timeline of the last decade recently, as I watched Moxie Marlinspike’s CyLab Seminar Series presentation on “New Tricks for Defeating SSL in Practice.”
Because, unlike Moxie’s earlier contribution,
SSLsniff, which issues Man-in-the-Middle (MITM) attacks on SSL, the fascinating work that Moxie talked us through in this particular presentation,
SSLstrip is not really about breaking SSL, it is about getting around SSL by exploiting weaknesses in the enveloping framework in which SSL is operating.
That’s what reminded me of those vendors and consultants who wanted to put security concerns to rest by assuring the public and the press that SSL was in place. It was the wrong answer to the wrong question then, and it, and its security marketplace equivalents, still are now.
And just as the real takeaway from Moxie’s talk was not so much the attacks he demonstrated, although they are indeed compelling, it is that independent research and pure hacker kulchur is alive and well, at
www.thoughtcrime.org and elsewhere in the shadows of cyberspace.
Here are some brief excerpts from Marlinspike's talk:
In his opening remarks, Moxie observed, "The title of the talk is kind of a misnomer because I am going to be talking about SSL in the context of the Web, so the title should be 'Tricks for Defeating HTTPS in Practice.'
During his discussion of the background, that is the development of SSLsniff, Moxie shared some insight into how to succeed in such research, "Personally, I find that when looking for security vulnerabilities, a good place to start are those places where developers probably don't know what they are doing, but feel really good about the solution they implement."
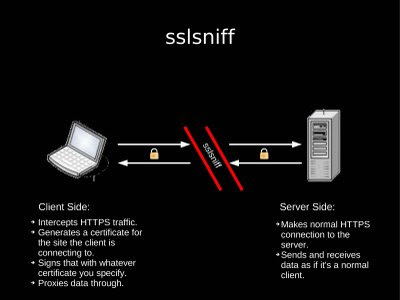
Before moving on to SSLstrip, Moxie reviewed SSLsniff's ongoing relevance:
"You'd be surprised who still doesn't check basic constraints. I have promised to talk more about this in the future, and I will.
"Even when people got warning dialogs in browsers that had been fixed, most of the time they'd just click through them. There is an interesting little sub-point there, most browsers would start validating certificates, and as soon as they found a problem, they would stop. They would pop up a dialog and say, 'there is a problem, do you want to continue?' You could do these interesting tricks. You could create a totally bogus certificate that expired two minutes ago. It has invalid signature, everything about it is wrong. But the second thing that most SSL implementations did was check the time stamp, to make sure it hadn't expired. So what would happen is that it would check the name on the certificate, which of course matches whatever you are trying to intercept, and then it would check the time stamp and say, 'Oh, this expired two minutes ago.' And it would pop up a dialog to the user, saying 'There is something wrong, this ticket expired two minutes ago.' So a lot of users would be thinking "Oh, everything is fine, it's just that this ticket expired just a couple of minutes ago, they just haven't got around to issuing a new certificate yet, this should be fine,' and they would click through it.
"SSLsniff is still useful as a general MITM tool for SSL. The folks who did the MD5 hash collision stuff last December (2008) used sslsniff to hijack connections once they'd gotten a CA cert."
And in concluding his remarks on SSLsniff, Moxie gave fair warning, "There are other uses yet to be disclosed another day."
Moving on to explore what led to his development of the SSLsniff tool, Moxie drew a distinction between "browsers then and now," pointing out that in the past they employed a "postivie feedback system" to re-assure the user about the presence of security (i.e., "a number of indicators deployed to designate that a page is secure, a proliferation of little lock icons, a URL bars that turn gold") as opposed to the "negative feedback system" used now (i.e., less emphasis on sites being secure, e.g., "the proliferation of little locks has been toned down, and Firefox's gold bar is gone," increased emphasis on alerting users to problems, e.g., "a maze of hoops that users have to jump through in order to access sites with certificates that aren't signed by a CA."
In assessing the implications of this shift from the attacker's perspective, Moxie concluded: "If we trigger the negative feedback, we're screwed. If we fail to trigger the positive feedback, it's not so bad."
In looking for opportunities to apply this maxim, Moxie next looked at the relationship between SSL and HTTP.
"How do people use SSL? Nobody types 'https://' or 'http' for that matter. People generally encounter SSL either by clicking on links or through 302s, which means that people only encounter SSL through HTTP. ... We can attack both of these points through an HTTP MITM."

In rapid success- ion, Moxie led the attendees through his iteration of SSLstrip.
In the first cut, SSLstrip simply attacked HTTP instead of SSL, with promising end results, "The server never knows the difference. Everything looks secure on their end. The client doesn't display any of the disastrous warnings that we want to avoid. We see all the traffic."
"We've managed to avoid the negative feedback, but some positive feedback would be good too," Moxie said, pushing further, "People seem to like the little lock icon thing, so it'd be nice if we could get that in there too."
So in the next iteration, Marlinspike's program would respond to a favricon request for a URL it had stripped by sending back its own little padlock icon.

In his further develop- ment of the program, Moxie also dealt with the problem of sessions: "Sessions expire, and it's not always clear when or why, but they don't usually expire right in the middle of an active session. So what we do now: When we start a MITM against a network, strip all the traffic immediately, but don't touch the cookies for 5 min (or some specified length of time). As the cookies go by, make note of the active sessions. After the time is up, start killing sessions, but only new sessions that we haven't seen before. These should be the “long running” sessions that won't be seen as suspicious should they disappear."

"The results were kind of astound- ing. In 24 hours, 114 Yahoo logins, 50 Gmail logins, 42 secure posts to Ticket Master, 14 Rapidshare accounts, 13 Hotmail accounts, 9 Paypal logins, 9 LinkedIn accounts, and 3 Facebook accounts, and many more. That means in 24 hours, I got 117 email accounts, 16 credit card numbers, 7 paypal logins, over 300 other miscellaneous secure logins. So I wondered, 'That's a lot data, but what is the success rate? How many people didn't submit their data? How many people got to whatever it is they wanted to log into and then didn't log in? So I modified it a little bit and ran it again for another 24 hour period, and this time, I logged the number of people who browsed to a page which would have had secure post and then didn't post data. So how many people browsed to the g-mail login and then didn't login? How many people browsed to the paypal login and then didn't login? ... I got a comparable number of secure posts, but the question is how many people balked? Zero. In a 24 hour period, not a single person browsed to a page with a secure post and didn't post data."
When Marlinspike presented these results at Blackhat in D.C., one of the responses he received was, "Well, OK, this is a problem with 'User Education,' users are ignorant, they do not know how to use the web."
Moxie did not think that "user education" was the real issue, and rightfully so.
To demonstrate the point, he went on to deliver the presentation at Blackhat Europe in Amsterdam, and before he did he ran SSLstrip on the network at the conference, intercepted over one hundred secure logins in a thirty minute period and selected ten of the passwords collected to include on a slide for display during his talk.
Bravo.
Stay tuned. Marlinspike is working on more.
Among the lessons learned from this research, "Lots of times the security of HTTPS comes down to the security of HTTP, and HTTP is not secure.
Some Other CyLab Seminar NotesCyLab Seminar Series Notes: User-Controllable Security and Privacy -- Norman Sadeh asks, "Are Expectations Realistic?"CyLab Seminar Series: Of Frogs, Herds, Behavioral Economics, Malleable Privacy Valuations, and Context-Dependent Willingness to Divulge Personal InfoCyLab Seminar Series Notes: Why do people and corporations not invest more in security?CyLab Research Update: Basic Instincts in the Virtual World?For information on the benefits of partnering with CyLab, contact
Gene Hambrick, CyLab Director of Corporate Relations: hambrick at andrew.cmu.edu














{kind=link}